La optimización de Big Data en Odoo es un asunto muy serio porque cuando Odoo es utilizado por grandes empresas, implica que usarán el sistema de manera extensiva y eso va de la mano con un crecimiento de datos muy rápido y sostenido. Obviamente, las tablas estándar con mayor impacto serán las que llamamos tablas "Lines" como:
sales_order_line
account_move_line
stock_move_line
El Problema
Para evaluar el impacto del crecimiento genérico de datos en estas tablas, imaginemos una empresa estándar con 10 sucursales y 2 personas de contabilidad validando 100 facturas cada una por cada día laboral. Seamos justos y establezcamos el número promedio de sales_invoice_line por factura en 10 artículos por factura. Los resultados serían los siguientes:
100 facturas X 10 artículos por factura = 1,000 líneas de factura.
1,000 líneas de factura generarán 1,000 líneas de producto + 100 líneas de impuestos + 100 líneas de monto total de la factura dentro del Sales Journal (o diario de ventas) si configuramos este último para escribir account_moves POR PRODUCTO, que es la única manera correcta de obtener valores de Dashboarding por cuenta o por producto, por categoría, etc. Esto resulta en 1,200 account_move_lines por usuario por día.
Multiplicado por 2 usuarios, esto nos da 2,400 entradas account_move_line por sucursal por día.
Multiplicado por 10 sucursales, esto nos da 24,000 entradas account_move_line por empresa por día.
Multiplicado por 25 días abiertos, obtenemos 24,000 X 25 = 600,000 account_move_lines por mes.
Anualmente, obtenemos 600,000 x 12 = 7,200,000
Superando los 3 millones de líneas, comenzarás a sentir un impacto importante en el rendimiento.
Arriba de 5 a 6 millones de líneas, serás severamente penalizados. Por supuesto, esto depende de tu hardware, tecnología de disco, disponibilidad de CPU, estrategia de listado o de espera, etc., pero en general, en el caso actual, se avecinan más problemas:
7,200,000 entradas account_move_line representan solamente facturas validadas, pero esto significa que la tabla sales_order_lines puede ser de 2 a 10 veces más grande dentro del mismo período porque también contiene cotizaciones. Seamos justos y consideremos que convertiste el 30% de las cotizaciones en ventas: la tabla sales_order_line será aproximadamente 3 veces más grande; estamos hablando aproximadamente de 21,000,000 de entradas por año.
Tendrás casi lo mismo en las tablas stock_move_lines.
Ni siquiera estoy hablando de MRP, que puede crear tablas aún más grandes junto con números de lote, etc., si el cliente también está haciendo producción.
Supongo que se trata de un sistema MONO COMPANY, o de lo contrario, terminarás con datos de diferentes empresas dentro de las mismas tablas. ¡Imagínate esto multiplicado por 3 empresas dentro de las mismas tablas!
Supongo que tienes dedicados un servidor y recursos por empresa, pero no siempre es así, ya que muchas personas mutualizan el alojamiento o hosting.
Ahora, si consideramos que tienes alrededor de 30 usuarios accediendo simultáneamente a estas básicas y muy importantes tablas, y un par de usuarios están intentando hacer Dashboarding mientras el resto intenta trabajar… pues…. ¡Olvídalo! Ve a comprar un café o inscribirte a clases de Zen.
Midiendo la Brecha de Rendimiento
Muchos de nuestros clientes, incluidos los departamentos de TI, otros socios de Odoo y desarrolladores independientes, nos han pedido que optimicemos sus implementaciones porque el sistema se estaba ralentizando. Pasé un tiempo jugando con lo siguiente para poder darte una idea real de la optimización de Big Data en Odoo. Mi kit de prueba constaba de lo siguiente:
1 CPU XEON E5 – 6 cores de 2Ghz
8 Gb de RAM
Disco duro SSD de 256 Gb
Ubuntu 16.04
PostgreSQL 9.5
Prueba realizada con y sin PgBouncer
Datos falsos generados para la ocasión dentro de las tablas account_move/account_move_line
Aquí están los resultados de mi medición de lo siguiente:
Seleccionar todos los Elementos del Journal (o registro), de todos los Journals.
Agrupados por período
Fecha de vigencia superior a...
Fecha de vigencia inferior a...
Con la SUMA total calculada para las columnas Crédito/Débito en la parte inferior.
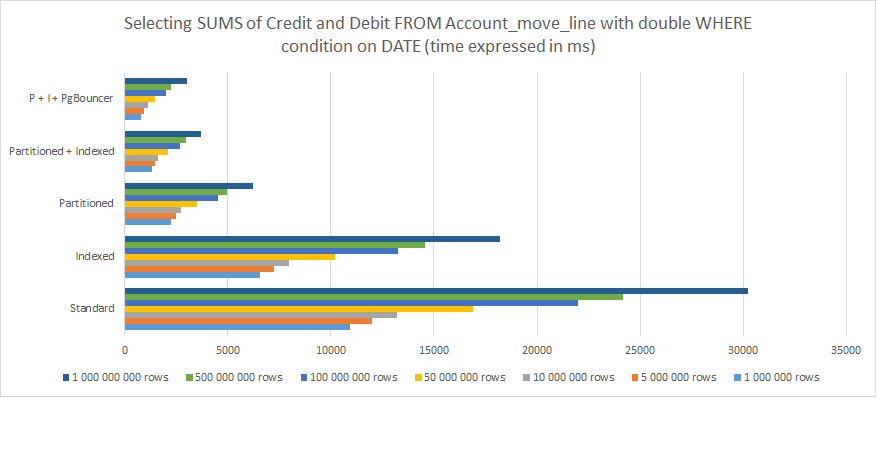
De lo anterior, se puede entender claramente que:
La Indexación ayuda, pero no es suficiente a largo plazo.
El particionamiento funciona mucho mejor.
El acoplamiento de particiones e indexación funciona aún mejor.
Acoplando particiones e indexación y asociádolos con PgBouncer se obtienen los mejores resultados.
Para 1,000,000,000 de filas, la diferencia entre una estructura estándar Odoo PostgreSQL y una optimizada con Particionamiento, Indexación y PgBouncer, cae de 30,000 ms (30 segundos) a menos de 3,000 ms (3 segundos). Sin embargo, ten en cuenta que esta es solo una solicitud de un solo usuario. Pon esto en perspectiva con 30 o más usuarios simultáneos, y comprenderás que esta es la diferencia entre un sistema que se ejecuta y uno que simplemente se agota sistemáticamente, y causa errores hasta que finalmente falla.
Si eres escéptico sobre el análisis anterior para la optimización de Big Data Odoo, echa un vistazo a esta publicación: PostgreSQL: Tabla particionada vs Tabla no particionada. Esto no está dedicado a Odoo y trata con tablas más simples dentro de PostgreSQL, pero el enfoque es muy sencillo y preciso, y las conclusiones son bastante idénticas.

¿Quieres optimizar un gran volumen de datos en tu sistema?
Implementando Su Estrategia Odoo de Optimización de Big Data
Si estás leyendo esta publicación significa que, o estás considerando proporcionar soluciones de Big Data con Odoo o PostgreSQL como base, o que ya estás experimentando lentitud. Sin embargo, ten en cuenta que la lentitud puede deberse a diferentes motivos:
Dejaste tu PostgreSQL configurado de forma predeterminada. Hay mucho que hacer en ese lado para explotar el verdadero potencial de tu servidor o clúster PostgreSQL, y la configuración predeterminada definitivamente debe reemplazarse con una estrategia apropiada de usos y recursos.
Tienes un problema de sesiones en lista de espera y de autenticación de HBA o ambos: aprende a usar PgBouncer.
Si tu caso no se aplica a ninguna de las razones anteriores, entonces probablemente necesites pasar a Indexación y Partición, y mis recomendaciones son las siguientes:
Ten en cuenta que la indexación puede resultar costosa en recursos, especialmente si juega con valores de cadena.
Poner la indexación en todas partes es un enfoque INCORRECTO. Solo colócala donde sepas que el ORM y su módulo son propensos a empujar y extraer valores.
Define una estrategia de partición desde el principio y no esperes hasta que tus tablas se vuelvan enormes. Tú CONOCES el perfil de tu cliente, la facturación, los usuarios y esto DEBE ser anticipado.
Tu estrategia de partición debe seguir las orientaciones del crecimiento de datos. Cada cliente es diferente. Este es siempre un proceso "por caso".
Aplica una lógica de estructura de tabla de particiones que siga la lógica de los activadores.
Ten cuidado con las reglas de activación mal definidas que pueden causar superposición de datos o bucles infinitos.
Las reglas de partición funcionan, pero por experiencia, los activadores simplemente funcionan MEJOR con Odoo. Por lo tanto, limítate a los desencadenantes.
Si tu versión de PostgreSQL es 11 o superior, te recomiendo que recurras a la herencia de particiones.
Sé amable con los desencadenantes. Si necesitas complejidad, colócalas en la función.
Estira tus particiones secundarias de acuerdo al patrón de Odoo o Data.
Utiliza las exclusiones de restricciones para optimizar la velocidad de tu consulta. Para poder hacerlo, recuerda estructurar tu partición de acuerdo con estos también.
Si ya tienes un sistema lento y necesitas re-segmentar tus datos a través de un proceso de optimización por partición de Big Data de Odoo, debes seguir las siguientes pautas:
Aplica también las recomendaciones anteriores.
Recuerda que Odoo no sabe que estás modificando la estructura de datos dentro de PostgreSQL. Hacerlo de la manera correcta implica que conservas todos los nombres de la tabla principal, columnas, formato de datos y restricciones entre tablas.
Realiza una suma de comprobación de tus datos antes y después de la re-segmentación o partición. SÍ, es básico; pero debes asegurarte de que todo esté ahí.
Recuerda prepararte también para el futuro. Dividir datos por año para datos pasados, por ejemplo, pero no dividirlos para los próximos años es un GRAN error. Recuerda que PostgreSQL irá tan lento como las solicitudes más lentas de todas. Entonces, si consideras dividir bien los últimos 5 años completos y luego dejas un gran lío como una tabla activa para todo el resto que sigue creciendo, no resolviste absolutamente nada, y solo ensuciaste las cosas. El rendimiento se degradará igualmente.
Port Cities - un Equipo Global con Experiencia en Optimización de Big Data
Si crees que esta optimización de Big Data de Odoo es demasiado compleja o especializada, entonces deberías considerar hacerla e integrarla con un equipo que tenga experiencia tanto en Odoo como en PostgreSQL. Port Cities tiene un equipo de 80 desarrolladores internos listos para ayudarte con la optimización de Big Data.
Contáctanos para obtener más información sobre cómo optimizar tus datos y mejorar el rendimiento de tu sistema a medida que tu empresa crece.
