大規模データのOdoo最適化は、非常に深刻な問題です。なぜならば、Odooが大企業で使用されているということは、システムを広範囲に使用しているということであり、それは非常に高速で持続的なデータ増加と密接に関係しているからです。もちろん、最も影響を受けるのは、「_lines」と呼ばれる標準テーブルです:
sales_order_line
account_move_line
stock_move_line
問題点
一般的なデータの増加がこれらのテーブルに与える影響を評価するために、10の支店と2人の経理担当者を持つ標準的な企業が、営業日ごとにそれぞれ100件の請求書を検証していると想像してみましょう。公平を期して、請求書1枚あたりのsales_invoice_lineの平均数を10件としましょう。その結果は次のようになります。
請求書100枚 X 1枚の請求書あたり10 品目 = 1000 請求行
1000件の請求行は、1000件の製品行+100件の税金の行+100件の請求書の合計金額の行をSales Journalの中に生成します。
2人のユーザーを掛け合わせると、1日1支店あたり2,400件のaccount_move_lineエントリとなります。
10支店を掛け合わせると、1日1社あたり24,000件の account_move_lineエントリが発生します。
これに25日の営業日をかけると、1ヶ月あたり24,000×25=600,000件のaccount_move_lineが発生します。
年間では、600,000×12=7,200,000です。
300万行を超えると、パフォーマンスに大きな影響が出るようになります。
500万から600万行を超えると、大きなペナルティを受けることになります。もちろん、これはハードウェア、ディスク技術、CPUの稼働率、キューイング戦略などに依存しますが、全体的に見て、今回のケースではさらに以下の問題が発生します:
7,200,000 account_move_line エントリは、純粋に有効な請求書を表しています。..... しかし、sales_order_lines テーブルには見積書も含まれているため、同じ期間に 2 倍から 10 倍の大きさになる可能性があることを意味します。公平を期して、見積書の30%を売上に変えたとすると、sales_order_lineテーブルは約3倍になります。ざっと見て、年間21,000,000本のエントリーがあるということになります。
また、stock_move_linesテーブルにも同様に多くのエントリがあります。
MRP(生産計画・管理)の話はしていませんが、顧客が生産を行っている場合、ロット番号などと一緒にさらに大きなテーブルを作成することもあります。
ここではMONO COMPANYシステムであると想定しています。そうでないと、同じテーブルの中に異なる会社のデータが入ってしまうことになります。これが、同じテーブルに3つの会社が入っていたらどうでしょう?
会社ごとに専用のサーバーと専用のリソースを持っていることが前提ですが、ホスティングを相互に利用する人も多いので、必ずしもそうとは限りません。
さて、これらの基本的で最も重要なテーブルに約30人のユーザーが同時にアクセスし、数人のユーザーがダッシュボードを作成し、残りのユーザーが仕事をしようとしていると考えてみましょう。....well.... もういいや。コーヒーを買うか、禅のクラスに申し込むかしましょう。
パフォーマンスギャップの測定
IT部門、他のOdooパートナー、独立系開発者を含む多くのお客様から、システムが遅くなっているので実装を最適化してほしいと依頼されました。私は、Odooにおけるビッグデータの最適化に関する真の洞察を提供するために、以下のことに時間を費やしました。私のテストキットは以下のもので構成されていました:
1 XEON E5 – 6 cores CPU 2Ghz
8 Gb of RAM
SSD Hard Drive 256 Gb
Ubuntu 16.04
PostgreSQL 9.5
Test done with and without PgBouncer
account_move/account_move_lineテーブル内に、この日のために生成されたフェイクデータ
以下は、私が測定した結果です:
すべてのジャーナルからすべてのジャーナルアイテムを選択
期間でグループ化
発効日が...より大きい
有効期限が...未満
下部の貸方/借方の列の合計SUMを計算した場合
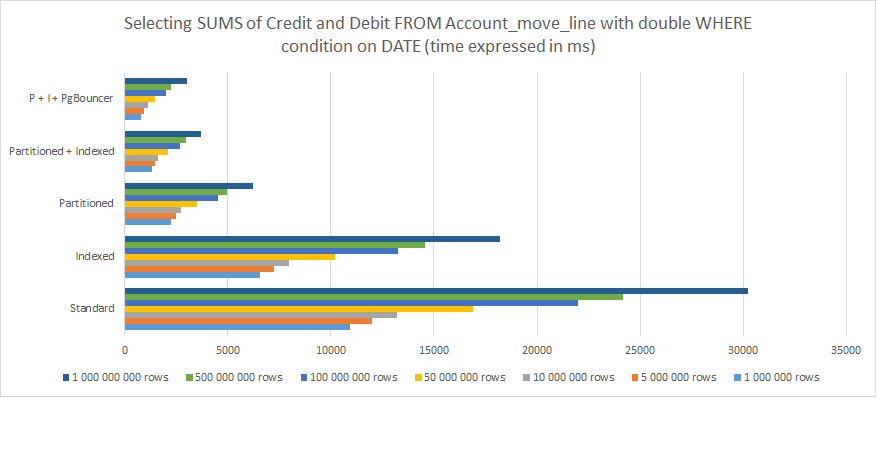
以上のことから、はっきりと理解できることがあります:
インデックスは有効だが、長期的には十分ではない。
パーティショニングの方がはるかに効果的。
パーティショニングとインデックスを組み合わせるとさらに効果的。
パーティショニングとインデックスを組み合わせ、PgBouncerと組み合わせることで最高の結果が得られる。
1,000,000,000行の場合、標準的なPostgreSQL Odoo構造と、パーティショニング、インデックス、PgBouncerによる最適化との差は、30,000ms(30秒)から3,000ms(3秒)以下にまで減少しました。しかし、これは1人のユーザーからの1つのリクエストに過ぎないことに留意してください。これを30人以上の同時使用ユーザーに置き換えて考えてみると、これが「稼働するシステム」と「システム的にタイムアウトやエラーが発生し、最終的にはクラッシュするシステム」の違いであることがわかります。
ビッグデータOdoo最適化のための上記分析に懐疑的な方は、この記事をご覧ください。 PostgreSQL:Partitioned Table vs Non Partitioned Table。これはOdooに特化したものではなく、PostgreSQL内のよりシンプルなテーブルを扱ったものですが、アプローチは非常にわかりやすく正確で、結論も全く同じです。

システム内の大量のデータの最適化をお考えですか?
ビッグデータのOdoo最適化戦略の実施
この記事をご覧になっているということは、OdooやPostgreSQLをベースにしたビッグデータソリューションの提供を検討されているか、あるいはすでに遅さを実感されているということだと思います。しかし、遅さには様々な原因があることを知っておいてください:
PostgreSQLの設定がデフォルト設定のままになっています。PostgreSQLサーバ/クラスタの真の可能性を引き出すためには、その面でやるべきことがたくさんあります。デフォルト設定を適切なリソースと使用方法に置き換える必要があります。
セッションキューイングとHBA認証の問題、またはその両方があります: PgBouncerの使用を学んでください。
もし、あなたのケースが上記の理由のどちらにも当てはまらないのであれば、おそらくインデックスやパーティショニングに踏み込む必要があり、私のお勧めは以下の通りです。
特に文字列の値を扱う場合、インデクシングはリソースが高くなる可能性があることに注意してください。
インデクシングをどこにでも置くのは間違ったアプローチです。ORMやモジュールが値を押したり引いたりしやすいと分かっている場所にのみインデックスを設置しましょう。
テーブルが巨大化するまで待つのではなく、最初からパーティショニング戦略を定義しましょう。顧客のプロファイル、回転率、ユーザーを知っているのだから、これを予測しなければならない。
パーティショニング戦略は、データ成長の方向性に従わなければなりません。すべての顧客は異なります。これは常に「ケースごと」のプロセスです。
トリガーのロジックに従ったパーティショニング・テーブル構造のロジックを適用する。
誤って定義されたトリガー・ルールは、データのオーバーラップや無限ループの原因となるので注意が必要です。
パーティショニング・ルールは機能しますが、経験上、Odooではトリガーの方がよく機能します。ですから、トリガーにこだわりましょう。
PostgreSQLのバージョンが11以上であれば、パーティション継承に頼ることを強くお勧めします。
トリガーには注意してください。複雑さが必要な場合は、代わりに関数に入れましょう。
OdooやDataのパターンに沿って子パーティションを伸ばしましょう。
クエリの速度を最適化するために制約除外を使用する。これを可能にするには、これらに従ってパーティショニングを構成することを忘れないでください。
すでに低速のシステムを使用していて、ビッグデータOdoo最適化パーティショニングプロセスによってデータを再セグメント化する必要がある場合は、以下のガイドラインに従ってください:
上記の推奨事項も適用してください。
OdooはあなたがPostgreSQL内のデータ構造を変更していることを知らないことを忘れないでください。正しい方法で行うことは、すべての親テーブル名、カラム、データフォーマット、テーブル間制約を保持することを意味します。
再セグメント化/分割の前後でデータをチェックサムする。はい、これは基本的なことです... しかし、すべてがそこにあることを確認する必要があります。
将来に向けての準備も忘れてはいけません。例えば、過去のデータを年ごとに分割しても、将来のデータを分割しないのは大きな間違いです。PostgreSQLは、最も遅いリクエストほど遅くなることを覚えておいてください。つまり、過去5年間の大量の完了したデータをうまく分割し、残りの増え続けるデータのために大きな混乱をアクティブなテーブルにしてしまうことを考えると、何も解決していません......物事を混乱させただけです。パフォーマンスも同じように低下します。
Port Cities - ビッグデータ最適化を専門とするグローバルチーム
もしあなたやあなたのチームが、ビッグデータのOdoo最適化は、たった一つのミスでデータの整合性が損なわれるかもしれないので、熱くて専門的すぎると思っているなら、OdooとPostgreSQLの両方の経験を持つチームによって、これを統合することを検討すべきです。Port Citiesでは、80人以上の社内開発者からなるグローバルチームが、お客様のビッグデータ最適化を支援する準備を整えています。
詳しくはお問い合わせください 企業の成長に合わせてデータを最適化し、システムのパフォーマンスを向上させる方法について。
