Tối ưu hóa dữ liệu lớn trong Odoo là một vấn đề rất được quan tâm khi Odoo được sử dụng bởi các công ty lớn, nghĩa là các công ty này sẽ phải sử dụng hệ thống rộng rãi, đi đôi với tốc độ tăng trưởng dữ liệu tăng lên theo cấp số nhân. Các dữ liệu sẽ bị ảnh hưởng nhiều nhất từ tốc độ tăng trưởng này là những bảng mà chúng tôi gọi là bảng “_lines”.
sales_order_line
account_move_line
stock_move_line
Đặt vấn đề
Để đánh giá tác động của việc tăng trưởng dữ liệu lên các bảng này, hãy tưởng tượng một công ty có 10 chi nhánh và 2 nhân viên kế toán xác thực 100 hóa đơn mỗi ngày. Giả sử bạn đặt số lượng dòng sales_invoice_line trung bình là 10 mặt hàng trên mỗi hoá đơn. Kết quả sẽ như sau:
100 hóa đơn X 10 mặt hàng trên mỗi hóa đơn = 1.000 dòng hóa đơn.
1.000 dòng hóa đơn sẽ tạo ra 1.000 dòng sản phẩm + 100 dòng thuế + 100 dòng tổng số tiền trong Nhật ký bán hàng nếu chúng ta định cấu hình các dòng này để viết account_moves cho MỖI SẢN PHẨM, đây là cách khả thi nhất để sau này có thể kéo các giá trị lên Bảng điều khiển (Dashboard) cho mỗi tài khoản hoặc mỗi danh mục sản phẩm v.v… Điều này đồng nghĩa với 1.200 account_move_lines cho mỗi người dùng mỗi ngày.
Nhân với 2 người dùng, tạo ra 2.400 mục nhập account_move_line cho mỗi chi nhánh mỗi ngày.
Nhân với 10 chi nhánh, tạo ra 24.000 mục nhập account_move_line cho mỗi công ty mỗi ngày.
Nhân với 25 ngày làm việc, chúng ta sẽ có 24.000 X 25 = 600.000 account_move_lines mỗi tháng.
Hàng năm, chúng ta sẽ tạo ra 600.000 x 12 = 7.200.000 dòng
Vượt quá 3 triệu dòng, bạn sẽ bắt đầu cảm thấy hiệu suất bị ảnh hưởng đáng kể.
Vượt quá 5 đến 6 triệu dòng, bạn sẽ bị hệ thống phạt nặng. Tất nhiên, điều này còn phụ thuộc vào phần cứng, công nghệ đĩa, tính khả dụng của CPU, chiến lược xếp hàng dữ liệu, v.v. nhưng nhìn chung, theo kinh nghiệm của chúng tôi, công ty sẽ có thể gặp phải những vấn đề khác như:
7.200.000 mục nhập account_move_line ở đây là dành cho các hóa đơn đã được xác thực… Điều này có nghĩa là bảng sales_order_lines có thể có số lượng dữ liệu lớn hơn từ 2 đến 10 lần trong cùng khoảng thời gian vì các bảng này còn chứa các báo giá. GIả sử rằng bạn chuyển đổi 30% số báo giá thành doanh số bán hàng: bảng sales_order_line của bạn sẽ lớn hơn khoảng 3 lần: nghĩa là khoảng 21.000.000 mục nhập mỗi năm mà chúng ta đang đề cập đến.
Số lượng dòng stock_move_line cũng nhiều tương tự.
Tôi thậm chí không nói về MRP (Material Requirements Planning) có thể tạo ra các bảng với dữ liệu lớn hơn cùng với số lô, v.v.… nếu khách hàng là một công ty sản xuất.
Tôi giả sử đây là hệ thống một công ty. Nếu không, bạn sẽ có dữ liệu từ nhiều công ty khác nhau trong cùng một bảng. Hãy tưởng tượng khối lượng dữ liệu khổng lồ cỡ nào nếu nhân với 3 công ty trong cùng một bảng!
Tôi giả sử công ty bạn có máy chủ chuyên dụng và tài nguyên dành riêng cho mỗi công ty, nhưng thực tế không phải lúc nào cũng vậy vì nhiều công ty sử dụng dịch vụ lưu trữ dùng chung (mutualized hosting).
Bây giờ, nếu chúng ta giả sử hệ thống của bạn có khoảng 30 người dùng truy cập đồng thời vào các bảng dữ liệu cơ bản này và một vài người dùng đang cố tạo Dashboard trong khi những khác đang làm việc trên hệ thống. Trong lúc chờ đợi, bạn nên đi mua cho mình một cốc cà phê hoặc đăng ký một lớp học Thiền.
So sánh hiệu suất
Nhiều khách hàng của chúng tôi bao gồm đội ngũ IT của các công ty, các Đối tác Odoo khác và các nhà phát triển độc lập đã yêu cầu chúng tôi tối ưu hóa việc triển khai của họ vì hệ thống của họ đang hoạt động chậm lại. Tôi đã dành một chút thời gian nghiên cứu cho một thử nghiệm sau đây để có thể cung cấp cho quý doanh nghiệp cái nhìn sâu sắc nhất về việc tối ưu hóa dữ liệu lớn trong Odoo. Bộ thử nghiệm của tôi bao gồm những thứ sau:
1 XEON E5 - 6 nhân CPU 2Ghz
8 Gb RAM
Ổ cứng SSD 256 Gb
Ubuntu 16.04
PostgreSQL 9.5
Test được thực hiện có và không có PgBouncer
Dữ liệu giả được tạo cho thử nghiệm này cho các bảng account_move / account_move_line
Các cài đặt của tôi như sau:
Chọn tất cả các bút toán trong Nhật ký từ Tất cả nhật ký
Nhóm theo khoảng thời gian
Ngày có hiệu lực lớn hơn…
Ngày có hiệu lực nhỏ hơn…
Với tổng SUM được tính cho các cột Phát sinh Có/Phát sinh Nợ ở dưới cùng
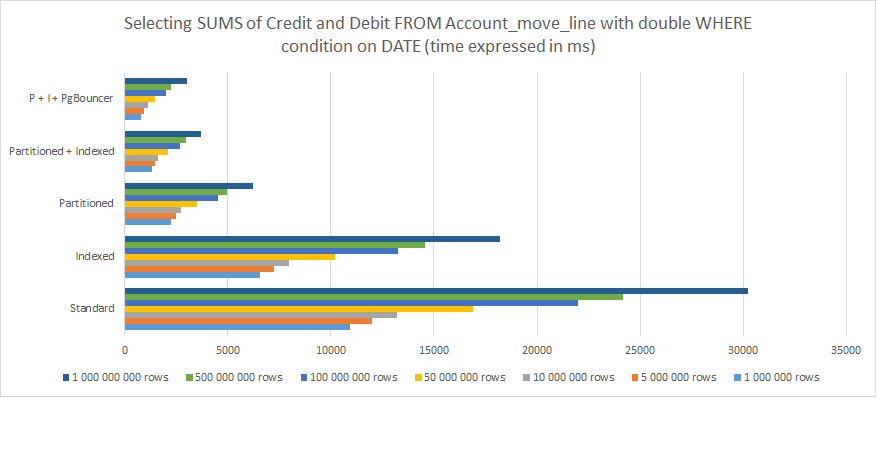
Từ những điều trên, ta có thể thấy rõ ràng rằng:
Lập chỉ mục (Indexing) giúp ích nhưng không đủ về lâu dài.
Phân đoạn dữ liệu (Partitioning) mang lại hiệu suất cao hơn.
Kết hợp Phân đoạn và Lập chỉ mục càng rút ngắn thời gian xử lý yêu câu
Kết hợp Phân đoạn và Lập chỉ mục và liên kết với PgBouncer mang lại kết quả tốt nhất.
Đối với 1.000.000.000 hàng, sự khác biệt trong hiệu suất thời gian giữa cấu trúc PostgreSQL Odoo tiêu chuẩn và Được tối ưu hóa với Phân vùng, Lập chỉ mục và PgBouncer giảm từ 30,000 ms (30 giây) xuống còn có 3,000 ms (3 giây). Tuy nhiên, hãy nhớ rằng đây chỉ là một yêu cầu từ một người dùng duy nhất. Đặt điều này trong quan điểm nếu bạn có 30 người dùng đồng thời trở lên, bạn sẽ hiểu đây là sự khác biệt giữa một hệ thống vận hành trơn tru và một hệ thống chỉ giết thời gian và liên tục gây ra lỗi cho đến khi gặp sự cố.
Nếu bạn còn nghi ngờ về phân tích trên đây về cách tối ưu hóa Big Data trên Odoo, hãy tham khảo bài đăng này PostgreSQL: Bảng có phân đoạn và Bảng không phân đoạn. Bài này không viết về Odoo và xử lý các bảng đơn giản hơn trong PostgreSQL nhưng cách tiếp cận rất đơn giản và chính xác, và các kết luận khá giống của tôi.

Bạn đang tìm cách tối ưu hóa khối lượng lớn dữ liệu trong hệ thống của mình?
Triển khai chiến lược tối ưu hóa Big Data trên Odoo
Nếu bạn đang đọc bài này, có nghĩa là bạn cân nhắc việc cung cấp các giải pháp dữ liệu lớn với Odoo hoặc PostgreSQL làm cơ sở hoặc hệ thống của bạn đang hoạt động chậm lại. Tuy nhiên, hãy lưu ý rằng điều này có thể đến từ những lý do khác nhau:
Bạn để PostgreSQL được cấu hình theo thiết lập mặc định. Trong trường hợp này, có rất nhiều việc bạn phải làm để khai thác tiềm năng thực sự của máy chủ / cụm PostgreSQL và cài đặt mặc định chắc chắn phải được thay thế bằng một chiến lược sử dụng và tài nguyên phù hợp.
Bạn gặp vấn đề về hàng đợi phiên và vấn đề xác thực HBA hoặc cả hai: bạn nên tìm hiểu cách sử dụng PgBouncer
Nếu trường hợp của bạn không nằm trong hai lý do trên, bạn cần phải kết hợp Lập chỉ mục (Indexing) và Phân đoạn dữ liệu (Partitioning) và các đề xuất của tôi như sau:
Lưu ý rằng việc lập chỉ mục có thể trở nên tốn kém, đặc biệt đối với các giá trị chuỗi.
Đặt Indexing ở khắp mọi nơi là một cách tiếp cận SAI. Bạn chỉ nên áp dụng ở nơi bạn đã cài đặt ORM (kỹ thuật chuyển đổi dữ liệu giữa các hệ thống - Object-Relational Mapping) và nơi mô-đun của bạn tương ứng với các giá trị đẩy và kéo.
Xác định chiến lược phân vùng ngay từ đầu và đừng đợi cho đến khi các bảng dữ liệu của bạn trở nên khổng lồ. Bạn cần thấu hiểu khách hàng của mình cũng như lường trước được doanh thu và số lượng người dùng của họ.
Chiến lược phân vùng của bạn phải tuân theo các định hướng tăng trưởng dữ liệu. Mỗi khách hàng đều khác nhau. Mỗi trường hợp có một quy trình riêng.
Áp dụng logic cấu trúc bảng phân vùng tuân theo logic của trình kích hoạt (trigger).
Cẩn thận với các quy tắc kích hoạt (Trigger) được xác định sai có thể gây ra chồng chéo dữ liệu hoặc vòng lặp vô hạn.
Quy tắc phân vùng mang lại hiệu quả… nhưng theo kinh nghiệm của tôi, trình Trigger chỉ hoạt động TỐT HƠN với Odoo. Vì vậy, chỉ cần dùng trình Trigger.
Nếu phiên bản PostgreSQL của bạn là 11 trở lên, thì tôi thực sự khuyên bạn nên sử dụng kế thừa phân vùng (inheritance partition).
Hãy cẩn thận với Trigger. Nếu bạn cần cấu hình phức tạp, hãy đặt nó vào hàm.
Kéo giãn phân vùng con của bạn theo mẫu Odoo hoặc Data.
Sử dụng Loại trừ Ràng buộc để tối ưu hóa tốc độ truy vấn của bạn. Để có thể thực hiện điều này, hãy nhớ cấu trúc phân vùng theo những loại trừ này.
Nếu hệ thống của bạn đã chậm sẵn và cần phân đoạn lại dữ liệu của mình thông qua quy trình phân vùng tối ưu hóa dữ liệu lớn Odoo, bạn nên làm theo các nguyên tắc dưới đây:
Áp dụng các khuyến nghị trên.
Hãy nhớ rằng Odoo không biết bạn đang sửa đổi cấu trúc dữ liệu bên trong PostgreSQL. Làm đúng cách sẽ giúp bạn bảo toàn tất cả các tên bảng mẹ, cột, định dạng dữ liệu và các ràng buộc giữa các bảng.
Tổng kiểm (checksum) dữ liệu của bạn trước và sau khi phân đoạn lại/phân vùng. Đây là điều cơ bản… nhưng bạn cần đảm bảo điều này.
Nhớ chuẩn bị cho dữ liệu trong tương lai. Ví dụ, chia nhỏ dữ liệu mỗi năm cho dữ liệu trong quá khứ nhưng không chia nhỏ cho những năm tới là một sai lầm LỚN. Hãy nhớ PostgreSQL sẽ hoạt động chậm bằng những yêu cầu chậm nhất. Vì vậy, nếu bạn xem xét việc chia nhỏ dữ liệu cho 5 năm vừa qua mà không thực điều này cho dữ liệu trong các năm tới sẽ chỉ khiến mọi thứ trở nên lộn xộn và làm hiệu suất suy giảm.
Port Cities - đội ngũ toàn cầu với kinh nghiệm tối ưu hóa Big Data trên Odoo
Nếu quý doanh nghiệp cho rằng đội ngũ nội bộ của mình chưa đủ kinh nghiệm và kỹ thuật chuyên biệt cho việc tối ưu hóa Big Data trên Odoo thì bạn nên cân nhắc việc outsource một đối tác có kinh nghiệm trong cả Odoo và PostgreSQL. Port Cities tự hào có một đội ngũ hơn 80 chuyên gia phát triển mạng trên toàn thế giới sẵn sàng giúp bạn tối ưu hóa Big Data.
Hãy liên hệ với chúng tôi để biết thêm thông tin về cách tối ưu hóa dữ liệu và cải thiện hiệu suất hệ thống khi công ty của bạn ngày càng phát triển.
